Medical AI is increasingly global, yet the models, and the data behind them rarely cross borders cleanly. This is the multi-site, multi-country reality of medical AI: whether a model is built to travel or quietly breaks at the next hospital and the next country, is decided in the design of the data system, long before deployment. Cancer care runs as the example throughout: data-hungry, population-sensitive, and global in its ambitions.
The multi-site, multi-country reality
A medical AI model that performs accurately where it was trained will often lose accuracy somewhere else. In a systematic review of deep-learning diagnostic tools, most lost performance on external data; some by as much as 0.60 on the standard scale [1]. For a diagnostic meant to guide treatment, a silent drop at a new site is a patient-safety and equity problem, and the cause is rarely the model; it is the data system. So, the question behind every design choice is simple: “will it travel?”. A tool validated for one setting is legitimate, but the danger is assuming performance moves with it, especially in oncology, where the ambition is to serve diverse patients across many sites and countries.
Why medical data doesn’t travel
Three factors differ between sites, and a model cannot, by default, tell them apart.
-
Biology and epidemiology: Tumour biology itself varies. EGFR mutations drive about half of lung adenocarcinomas in East Asian patients (51% in a seven-country study, but just 22% of its Indian patients) versus 10–15% in Western cohorts [2,3]. The genomic record that underpins risk models is roughly 79% European-ancestry though Europeans are about 16% of the world [4].
-
Acquisition: Scanners, stains and fixation imprint a site “signature” that models read instead of disease; they can identify the submitting institution from a slide with near-perfect accuracy [5], and a single surgical skin-marking cut a melanoma classifier’s specificity from 84% to 46% [6].
-
Shortcuts: a COVID-19 classifier lost half its performance at a new hospital because it had learned positioning cues, not pathology [7].
This is not hypothetical for cancer: on breast and lung subtyping and glioma mutation prediction, whole-slide-image models showed performance gaps between demographic groups of up to roughly 16 percentage points, extending beyond race to factors such as age and income, which self-supervised foundation models reduced but did not eliminate [8]. The catch is that a model can post a strong average while quietly failing a subgroup; aggregate metrics hide disparity unless performance is stratified [9]. “Not interchangeable” does not always mean “pool everything”; but it always means difference must be measured, never assumed away.
The barriers are structural, not just technical
When a model fails at a new site, the first instinct is to blame the data: too little of it, or too messy. More and cleaner data helps, but it is not the core problem: even complete, well-curated data from many countries cannot simply be pooled. The obstacles are structural, not merely technical, and three problem-classes sit in the way.
-
Standards: Even with DICOM for slides and FHIR for records, semantic interoperability is unsolved: terminologies such as SNOMED CT and LOINC are applied inconsistently, and mapping local codes onto a common model is lossy, continuous work that, at scale, spans hundreds of data sources across dozens of countries [10].
-
Clinical workflows: Who gets tested, when, and by which referral pathway shapes the data before any model sees it.
-
Governance and law: GDPR, the EU AI Act, the IVDR and MDR, and the European Health Data Space are often cast as friction, but they encode legitimate interests in privacy, accountability and sovereignty. You cannot retrofit your way past these; you have to design for them, which is where a system, not just a dataset, begins to matter.
Harmonisation that preserves context: the blueprint
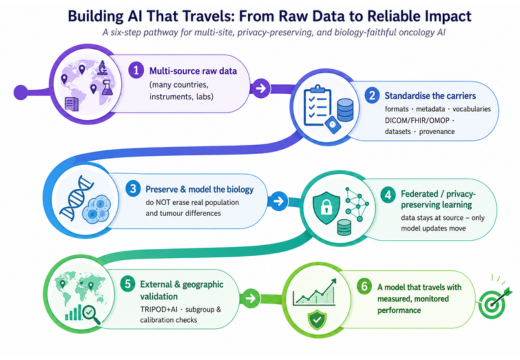
Figure: A six-step pathway for building oncology AI that travels from harmonising multi-source raw data and standardising carriers (DICOM, FHIR, OMOP), through preserving biological and population variation and enabling federated, privacy-preserving learning, to external geographic validation and continuous performance monitoring.
The discipline reduces to one line: standardise the carriers, preserve the biology. A system that travels is layered: an immutable raw zone; a harmonised zone where OMOP, FHIR and DICOM carry data with its provenance, but do not pretend to resolve clinical meaning [10]; and an analysis-ready zone. Four choices separate a system that scales from one that merely stores: identity resolution across hospitals (source IDs collide between countries); temporal integrity (stage, grade and biomarker status evolve, so they are versioned, not overwritten); ground truth treated as part of the system (clinical labels are inferred and vary between observers (in oncology, stage, response and biomarker status especially) so variability and missingness are measured, not assumed); and lineage plus a model-validation registry tying each model version to its data provenance and its per-site, per-subgroup performance. Where data cannot move, models can: federated learning trains across institutions by exchanging only model updates; the largest such study spanned 71 institutions on six continents [11]; backed, as risk dictates, by secure processing environments and privacy-preserving derivatives such as synthetic data. Only with context preserved this way can cross-border development and validation be credible.
Inclusive data is a performance requirement for the population you serve
Diversity is not a virtue in the abstract; it is a performance requirement relative to whom the model must serve, and that cuts both ways. Today’s data is narrow: one review found US training cohorts drew 71% of patients from just three states [12], and genome-wide studies remain about 6% East Asian and under 1% South Asian, a fifth and a quarter of humanity [13]. For a model meant to travel, breadth like this is exactly what buys robustness across populations. But for a single-country or largely mono-ethnic deployment, global diversity may matter less than depth in that population; and a focused, protected-group model can outperform a diluted “diverse” one for its own patients [14].
This is where a multi-country data system earns its keep: a sufficiently covered, well-governed pool can serve both demands at once, reframing the trade-off as a question of scope: pool across many countries for the breadth a global product needs, or slice by country or ancestry for the depth a national deployment needs; a diverse model or a focused one, as the intended use demands. The same system serves the multinational developer and the national, mono-ethnic programme; you need not fix the data strategy up front, only build the system that can do both.
Designed for borders, and kept valid, from day one
Multi-country capability is hard to retrofit because the binding constraints are legal and evidentiary, not merely technical, and because validation is not a launch event. Under the EU AI Act, diagnostic AI built into a regulated device is generally high-risk, and Article 10 requires training and validation data to be representative of the intended-use population, with demographic and geographic coverage documented and bias mitigated [15]. That standard (representativeness for the population served, not a global-diversity quota) is also why national reach matters in practice: there is no fixed “share of national data” rule, but national pathways increasingly require local evidence: France’s Forfait Innovation requires real-world evidence gathered in French hospitals before reimbursement, and Germany’s DiGA “fast-track” requires demonstrated benefit in German care. GDPR keeps health data bound: special-category processing needs a lawful basis and an Article 9 condition, pseudonymised data remain personal, and moving it outside the EEA triggers transfer rules [16]. The European Health Data Space adds governed access through national bodies inside secure processing environments, not an open data lake [17]. And because deployed models drift across populations, scanners, treatment regimens and coding, a working system validates continuously: transparent reporting of external and, where relevant, geographic validation up front [18], then subgroup dashboards, recalibration, rollback and change control, with reporting principles such as FUTURE-AI spanning the lifecycle [19]. Regulators are formalising the same logic through pre-specified, governed change plans that let a model improve without a wholly new review each time [20]. None of this can be bolted on after launch.
The system is the strategy
Heterogeneity in medical data is not noise to be filtered out; it is information to be governed and tested. The organisations that field medical AI worth trusting will not be those with the single largest dataset, but those whose systems can answer, for any new population: do we hold data representative of the people it will serve, is its provenance documented, has performance been validated here, and who benefits?
-
Cohort & ground truth: Diagnosis, stage, line of therapy, biomarker status and endpoints explicitly defined, with labels adjudicated for inter-observer variability and missingness.
-
Coverage & linkage: The relevant sources connected, with reliable identity resolution across sites and modalities.
-
Breadth or depth, by intended use: Can the system pool across countries for generalisation and slice to a population representative of the deployment site?
-
Temporal integrity: Evolving stage, grade, biomarker and treatment represented over time.
-
Privacy by risk: Federated learning, secure processing environments, differential privacy and synthetic data chosen by risk, not by label.
-
Lifecycle controls: Drift monitoring, subgroup dashboards, recalibration, rollback and audit logs after deployment.
-
Compliance & local evidence: Representativeness for the intended-use population, controlled model change, and the local real-world evidence national pathways require.
Build the system to meet that test: pool for breadth, slice for depth, harmonise without flattening, and stay validated across borders. Clinical trust and market access become achievable; the durable advantage is the governable, multi-country evidence base, not the model. Multi-country capability, like clinical validity itself, is a property of the system. It has to be designed in.
That is the work PAICON is committed to: building globally representative, harmonised and governed data foundations for medical AI across many countries, institutions and populations, and increasingly disease-agnostic, from oncology outward; so that AI can be developed, validated and trusted wherever it is needed, not only where it was born.
References
-
Yu AC, Mohajer B, Eng J. External validation of deep learning algorithms for radiologic diagnosis: a systematic review. Radiol Artif Intell. 2022;4(3):e210064. https://pubs.rsna.org/doi/full/10.1148/ryai.210064
-
Shi Y, Au JS, Thongprasert S, Srinivasan S, Tsai CM, Khoa MT, et al. A prospective, molecular epidemiology study of EGFR mutations in Asian patients with advanced NSCLC of adenocarcinoma histology (PIONEER). J Thorac Oncol. 2014;9(2):154-162. https://pmc.ncbi.nlm.nih.gov/articles/PMC4132036/
-
Midha A, Dearden S, McCormack R. EGFR mutation incidence in NSCLC of adenocarcinoma histology: a systematic review and global map by ethnicity (mutMapII). Am J Cancer Res. 2015;5(9):2892-2911. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4633915/
-
Martin AR, Kanai M, Kamatani Y, Okada Y, Neale BM, Daly MJ. Clinical use of current polygenic risk scores may exacerbate health disparities. Nat Genet. 2019;51(4):584-591. https://www.nature.com/articles/s41588-019-0379-x
-
Howard FM, Dolezal J, Kochanny S, Schulte J, Chen H, Heij L, et al. The impact of site-specific digital histology signatures on deep learning model accuracy and bias. Nat Commun. 2021;12:4423. https://www.nature.com/articles/s41467-021-24698-1
-
Winkler JK, Fink C, Toberer F, Enk A, Deinlein T, Hofmann-Wellenhof R, et al. Association between surgical skin markings in dermoscopic images and diagnostic performance of a deep learning convolutional neural network for melanoma recognition. JAMA Dermatol. 2019;155(10):1135-1141. https://jamanetwork.com/journals/jamadermatology/fullarticle/2740808
-
DeGrave AJ, Janizek JD, Lee SI. AI for radiographic COVID-19 detection selects shortcuts over signal. Nat Mach Intell. 2021;3(7):610-619. https://www.nature.com/articles/s42256-021-00338-7
-
Vaidya A, Chen RJ, Williamson DFK, Song AH, Jaume G, Yang Y, et al. Demographic bias in misdiagnosis by computational pathology models. Nat Med. 2024;30:1174-1190. https://www.nature.com/articles/s41591-024-02885-z
-
Montezuma D, Porz R, Ameisen D, L’Imperio V, Serbanescu MS, Temprana-Salvador J, et al. Unbiased artificial intelligence: addressing bias in computational pathology. Mayo Clin Proc Digit Health. 2025;3(4):100302. https://www.mcpdigitalhealth.org/article/S2949-7612(25)00109-9/fulltext
-
Reich C, Ostropolets A, Ryan P, Rijnbeek P, Schuemie M, Davydov A, et al. OHDSI Standardized Vocabularies—a large-scale centralized reference ontology for international data harmonization. J Am Med Inform Assoc. 2024;31(3):583-590. https://pmc.ncbi.nlm.nih.gov/articles/PMC10873827/
-
Pati S, Baid U, Edwards B, et al. Federated learning enables big data for rare cancer boundary detection. Nat Commun. 2022;13:7346. https://www.nature.com/articles/s41467-022-33407-5
-
Kaushal A, Altman R, Langlotz C. Geographic distribution of US cohorts used to train deep learning algorithms. JAMA. 2020;324(12):1212-1213. https://pubmed.ncbi.nlm.nih.gov/32960230/
-
Fatumo S, Chikowore T, Choudhury A, Ayub M, Martin AR, Kuchenbaecker K. A roadmap to increase diversity in genomic studies. Nat Med. 2022;28(2):243-250. https://www.nature.com/articles/s41591-021-01672-4
-
Puyol-Antón E, Ruijsink B, Piechnik SK, Neubauer S, Petersen SE, Razavi R, King AP. Fairness in cardiac MR image analysis: an investigation of bias due to data imbalance in deep learning based segmentation. In: MICCAI 2021. LNCS vol 12903. p. 413-423. https://link.springer.com/chapter/10.1007/978-3-030-87199-4_39
-
European Parliament, Council of the European Union. Regulation (EU) 2024/1689 (Artificial Intelligence Act) — see Article 10. Off J Eur Union. 2024. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
-
European Parliament, Council of the European Union. Regulation (EU) 2016/679 (General Data Protection Regulation). Off J Eur Union. 2016;L 119:1-88. https://eur-lex.europa.eu/eli/reg/2016/679/oj
-
European Parliament, Council of the European Union. Regulation (EU) 2025/327 on the European Health Data Space. Off J Eur Union. 2025. https://health.ec.europa.eu/ehealth-digital-health-and-care/european-health-data-space-regulation-ehds_en
-
Collins GS, Moons KGM, Dhiman P, Riley RD, Beam AL, Van Calster B, et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. 2024;385:e078378. https://www.bmj.com/content/385/bmj-2023-078378
-
Lekadir K, Frangi AF, Porras AR, Glocker B, Cintas C, Langlotz CP, et al. FUTURE-AI: international consensus guideline for trustworthy and deployable artificial intelligence in healthcare. BMJ. 2025;388:e081554. https://www.bmj.com/content/388/bmj-2024-081554
-
US Food and Drug Administration. Marketing submission recommendations for a predetermined change control plan for AI-enabled device software functions (final guidance). 2025. https://www.fda.gov/regulatory-information/search-fda-guidance-documents/marketing-submission-recommendations-predetermined-change-control-plan-artificial-intelligence